What is data processing?

The world is becoming increasingly data-driven. In fact, it's estimated that for every person on earth, 1.7 megabytes of data is created every second. Every minute of every day, data helps people and organisations make sense of increasingly complex information, and it also helps them make critical decisions. If you’re interested in learning how to use data to make sense of trends, and then predict what might happen in the future, an understanding of data processing is essential.
Data processing overview
What is data processing? It’s the conversion of data and raw information into a desirable, usable, and understandable format, usually over multiple steps. The steps generally occur through a data processing device, such as a computer.
Data processing steps include collecting, recording, organising, structuring, storing, retrieving, using, and disseminating. Processed data may take the form of an image, graph, table, chart, or any other format. Data processing encompasses a range of tasks, from automatically sending promotional emails to video recording.
Why is data processing important?
Data is critical to helping businesses and people make important decisions every day. For example, a baby clothing company may use customer purchase behaviour to better target its online advertising and grow its business.
What makes processing that data important though? Here are four crucial reasons:
1. Helps information become more reliable and accurate
Data processing helps people sort through information quickly, reliably, and accurately. Thousands of pieces of data can be processed in minutes, and data can be organised in such a way that files are checked, and invalid or corrupted data is deleted or minimised. For example, social media sites are able to make sense of the behaviour of millions of different users on their platforms and can aggregate this information so that advertisers can target exact demographic criteria.
2. Helps store, distribute, and report on information
Data processing helps increase data storage space, as well as distributing and reporting on information. Processed data comes in formats that people can easily read and understand, and it can be useful in myriad ways. For example, data on weather averages or even sales figures can be turned into graphs or charts, and then presented in a way that allows predictions about what might happen in the future.
3. Enables better analysis and presentation of data
Processed data is much easier to analyse than raw data, and it can be presented in many different formats so that the outcome of an analysis can be easily interpreted. For example, raw data can be converted into graphs or charts to help identify trends.
4. Helps businesses be productive, reduce costs, and increase profits
Ultimately, raw data can be a great source of competitive advantage for businesses. It can help them become more efficient and effective, automate tasks, and analyse information from the past to predict trends and plan for the future. For example, emails can be automatically sent to customers at certain times, or past employee performance can be used to predict what kind of people should be hired.
What are the steps involved in data processing?
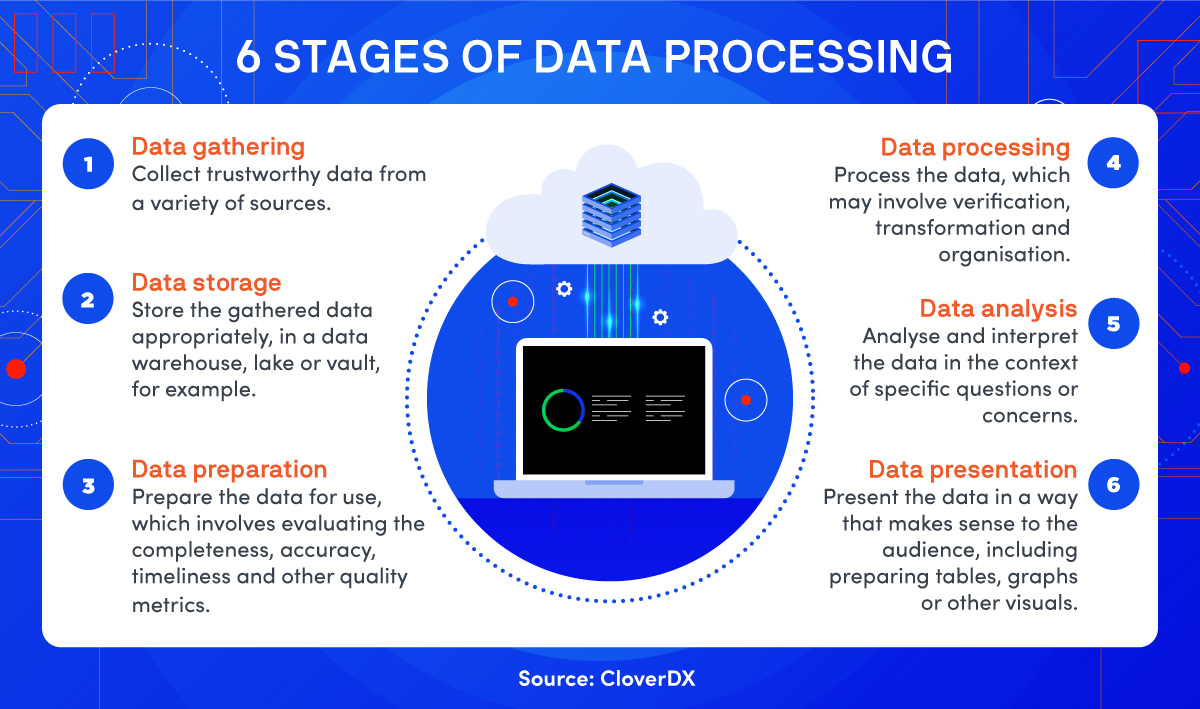
The process of converting raw data into useful information involves multiple steps. Here are the six steps to take when processing data:
1. Data gathering
In the data gathering step, computer processors pull data from available data sources, which may include data warehouses or data lakes (centralised repositories that allow companies to house data). For data gathering to work effectively, data needs to be trustworthy. In sum, it needs to be high-quality data that accurately represents a real-world construct to facilitate the rest of the process.
2. Data storage
In the data storage step, the data that’s been gathered is stored. Data needs to be stored in accordance with data protection legislation. Data also needs to be stored so that those who need to use it can quickly and easily access it.
Given how important and sensitive data can be, countries have developed legislation to protect it. An example of such legislation is the General Data Protection Regulation (GDPR). Legislation such as the GDPR sets out guidelines for the collection and processing of personal information from individuals who live in the European Union; similar legislation exists in countries all over the world.
3. Data preparation
In the data preparation step, the raw data is cleaned and organised, as well as checked for errors. The main purpose of this step is to eliminate redundant, incomplete, or inaccurate data and begin the process of creating higher quality data that are then translated into intelligent information, providing quality insights numerous people can access and understand.
4. Data processing
In the data processing step, data that’s been gathered and prepared is processed. Processing is usually completed using machine learning algorithms or other types of computer processing. The actual process may vary, depending on the ultimate source of the data (for example, whether the data is coming from data lakes or social networks) and also what the intended use of the data needs to be (for example, whether the data needs to be used for a medical diagnosis or for targeted advertising).
5. Data analysis
In the data analysis step, depending on how data is processed, data analysis can occur either simultaneously with processing or as a separate concern. If data analysis is a separate concern, computers or humans may conduct the analysis.
6. Data presentation
In the data presentation step, data is in an easily readable form, for example, a graph, a video, or an image. Data is readily accessible to those who need it, and it can be used for decision-making.
What are the different types of data processing?
Data processing is complex. The type of data processing is important as it helps determine how reliable the end output is — that is, whether the output can be trusted on its own or whether it needs to be further analysed and checked.
Here are the five main types of data processing:
Transaction processing
Transaction processing is used in important situations, such as those that may have adverse business consequences if the processing doesn’t occur. An example of this would be stock exchange transactions.
As transaction processing is often urgent, data availability is important for a business. Keep these important considerations in mind:
- Hardware: A transaction processing system needs to have redundant hardware. Hardware is redundant when it allows for partial failures. Redundant components can be automated to ensure that a system keeps running.
- Software: To ensure smooth transaction processing, software needs to recover quickly from failure. Fast recovery is typically achieved through transaction abstraction in which uncommitted transactions are aborted. In a stock exchange, this means that if data isn’t processed, a buy or sell fails.
To expand on this example, if data is unable to be processed in real time, you stand to lose thousands of dollars on risky trades, as market conditions can change quickly.
Distributed processing
Given the increasing complexity of data, a given data set is often too big to fit on a machine; that is, too much data needs to be processed in one place, so other processors need to be used. The term “distributed processing” refers to the process of large data sets being broken down and then distributed to multiple machines using the Hadoop Distributed File System (HDFS).
Distributed data processing is good from a risk mitigation perspective as it has a high fault tolerance. If one network fails, the data can be processed elsewhere.
Distributed data processing is also less expensive – businesses don’t need to invest in extensive mainframe hardware.
Real-time processing
Real-time processing is the process in which the output from data processing occurs in real time. This type of processing is similar to transaction processing. However, the two types of processing differ in how they handle data loss.
Real-time processing computes incoming data quickly. If it encounters an error, it ignores it and moves on to the next data set. In transaction processing, however, the processing aborts, and then reinitialises. For this reason, real-time processing is best when an approximate outcome is sufficient. In the stock exchange example used earlier, an “error” or an incorrect buy wouldn’t be acceptable, whereas in other data processing, this might suffice.
Batch processing
In batch processing, chunks of data are stored over a period of time, and then analysed together in batches.
This type of processing requires a large volume of data, for example, sales figures over a period of years. The reason is that only accurate insights can be garnered with a lot of data if it needs to be processed in batches; for example, it wouldn’t be possible to generate averages and potential future insights from only a few days’ worth of sales averages.
Due to the large volume of data involved, batch processing can take time, but it can also save on computational resources. This type of processing is best for when accuracy is more important than speed.
Multiprocessing
The final type of data processing, multiprocessing (also known as on-premises processing), involves two or more data processors working on the same data set. In multiprocessing, different processors are in the same system or at least in the same geographical location. This means that if a failure occurs, a close-by system can take over.
This type of processing is ideal for sensitive information, but it can be more costly.
What are some examples of data processing in use?
Data processing provides many critical functions, but it can be difficult to understand without real-life examples. Here are several real-life examples of data processing you can use in business and the community:
Marketing
When people browse the internet, they agree to use cookies that track which websites they visit and what they do on them. Search engines and social media companies process this data and use the output to provide advertisers with information on their target markets and their online behaviours.
Transportation
Data processing is particularly powerful in logistics. When a customer orders something online, the parcel is prepared and scanned at a factory, and customer details are inputted. Then, as the parcel makes its way along the customer journey, the customer is automatically notified of where it’s being scanned at different points.
Crime forecasting
Data processing can also help protect citizens from crime. Police can use data on previous crimes, including the type of crime committed in an area, to predict future trends. Police can also use data processing to track criminals and understand their whereabouts.
Health care
Data processing is helping doctors better serve patients and understand their needs. Patient data can be processed and used in multiple ways, for example, to predict the likelihood of certain ailments and to create personalised preventive plans.
Cybersecurity
Data processing is extremely powerful in regards to cybersecurity. Online, data is being recorded every second of every day. For that reason, processors understand what data patterns are usually recorded and can detect anomalies in real time. This can be particularly useful when hackers are trying to obtain sensitive information, as processors are able to detect anomalies quickly and activate particular cybersecurity measures.
Banking and finance
Banking and financial information are particularly sensitive, and it can be particularly harmful if it gets into the wrong hands. For this reason, data processing in the banking and financial industry is particularly important.
Data processing can help machines identify fraud attempts, such as password theft, and can help mitigate the risk.
Media
Data processing in media can help create a better experience for users. For example, when you use Spotify, the music app stores information about what you listen to. The data is then processed and compared to the music-listening experiences of millions of other users. The output comprises personalised recommendations, based on the data gathered about what sort of music you listened to in the past.
Education
Education benefits from data processing, too. For example, often student test results only make sense in the aggregate — in comparison to a large number of other results.
For this reason, data processing can be helpful in rating students in a way that takes into account everyone else’s progress. That is, it can help teachers benchmark what underachieving, achieving, and excellent look like.
What tools do data analysts use?
To effectively process data, analysts use many different tools. Here are several data processing tools that data analysts use regularly:
Business analysis tools
Business analysis tools, also known as business intelligence (BI) tools, are one of the most popular tools. They assist with business analysis, and they help analyse, monitor, and report on data output.
Business analysis tools ensure that solutions can be adjusted to different knowledge levels. These types of tools are also useful as they don’t require extensive involvement from an information technology (IT) or a coding team.
Statistical analysis tools
Statistical analysis tools use various statistical techniques to generate important data insights. They use multiple programming languages to manipulate and explore data, and they also use multiple coding languages to run different scenarios and create complex models.
The output of these tools is often complex analysis that’s best for a data scientist to interpret.
General-purpose programming languages
General-purpose programming can be used for data processing in which the processing needs to solve multiple data problems.
Programmers usually hand-code this type of data processing, so it can be complex. Programmers use a combination of letters, numbers, and symbols to create rules for data processing. The rules are generally written in codes such as C#, Java, PHP, Ruby, or Python.
SQL consoles
SQL consoles use the SQL programming language to manage and query data. This data is usually held in databases, and this type of processing is particularly effective for structured data. A SQL console is a versatile tool as it can be used to run multiple different data scenarios and create effective business cases to make a certain decision. Running SQL helps data analysts understand the relationship between different data sets.
Data modelling tools
Data modelling tools allow data analysts to create models that help structure information on databases and design business systems around them. Data modelling tools use diagrams, symbols, and text and help show how data flows and how data sets relate to one another.
Data modelling tools can help determine the exact nature of information and its importance.
Further resources
For more information on tools that data analysts use, please see:
- Stitch, Top 25 tools for data analysis and how to decide between them
- K2 Data Science & Engineering, Tools every data analyst should know
- Software Testing Help, 10 best data analysis tools for perfect data management

What skills are required to be a successful data analyst?
Given the critical role of data processing, many people aspire to a career in data analysis. What skills are required to be a successful data analyst? Here are four key skills you’ll need if you’re an aspiring data analyst:
High level of mathematical ability
Given that data analysis is usually quite literally about the numbers, it isn’t surprising that to be a successful data analyst, mathematical ability is critical. A high level of mathematical ability refers to the ability to use mathematics to solve problems, reason, and analyse information.
Programming languages
For data analysts to conduct their data processing tasks, they must know SQL, Oracle, or Python. These programming languages help data analysts perform powerful statistical analyses and use predictive analytics on more complex data sets. Successful data analysts require skills in at least one of these programming languages.
Ability to analyse, model, and interpret data
Data processing ensures that output is understandable. However, data analysts need to do more than simply read results. Data analysts need to learn to tell a compelling story from data, and for this reason, they need to understand how to analyse, model, and interpret different data sets.
This skill could take many forms, but it needs to include the ability to turn complex data output into easily readable and compelling business cases and reports.
Artificial intelligence (AI) and machine learning skills
Computers, although taking care of a lot of data processing, aren’t foolproof. For this reason, data analysts need to understand how AI and machine learning work. They also need to understand statistical programming to troubleshoot any issues that may arise.
Further resources
For more information on skills required to be a successful data analyst, please see:
- Dataquest, Data analyst skills — 8 skills you need to get a job
- Seek - Data Analyst
- BeamJobs, Top 5 data analyst skills employers want in 2021
Data processing: the function of the future?
Every day, more and more data is being created and processed around the world. For this reason, data processing and data analysts are becoming increasingly critical to the functioning of society.
Data helps businesses and people make better decisions. Going forward, its expert analysis won’t just be a nice-to-have, but a must-have, to ensure that businesses remain competitive and make the most informed and best decisions.
Secure your career in a data-driven world with a Master of Business Administration from UTS Online.





